
캐시란?
캐시(cache)는 데이터를 미리 복사해 놓는 임시 저장소이자 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리를 말한다. 이를 통해 데이터를 접근하는 시간이 오래 걸리는 경우를 해결하고 무언가를 다시 계산하는 시간을 절약할 수 있다.
실제로 메모리와 CPU 사이의 속도 차이가 너무 크기 때문에 그 중간에 레지스터 계층을 둬서 속도 차이를 해결한다.
이렇게 속도차이를 해결하기 위해 계층과 계층사이에 있는 계층을 캐싱 개층이라고 한다.
예를 들어 캐시 메모리와 보조기억장치 사이에 있는 주기억장치를 보조기억장치의 캐싱 계층이라고 할 수 있다.
지역성의 원리
캐시 계층을 두는 것 말고 캐시를 직접 설정할 수 있다.
이는 자주 사용하는 데이터를 기반으로 설정해야 한다. 그렇다면 자주 사용하는 데이터에 대한 근거가 되는 것은 무엇일까?
바로 지역성이다. 지역성은 시간 지역성(temporal locality)과공간 지역성(spatial locality)으로 나뉜다.
시간 지역성
시간 지역성은 최근에 사용한 데이터를 다시 접근하려는 특성을 말한다. 예를 들어 for 반복문으로 이루어진 코드 안의 변수 i에 계속해서 접근이 이루어질 때, 여기서 데이터는 변수 i이고 최근에 사용했기 때문에 계속 접근해서 +1을 연이어하는 것을 볼 수 있다.
let arr = Array.from({length : 10}, ()=> 0);
console.log(arr)
for (let i = 0; i < 10; i += 1) {
arr[i] = i;
}
console.log(arr)
/*
[
0, 0, 0, 0, 0,
0, 0, 0, 0, 0
]
[
0, 1, 2, 3, 4,
5, 6, 7, 8, 9
]
*/공간 지역성
공간 지역성은 최근 접근한 데이터를 이루고 있는 공간이나 그 가까운 공간에 접근하는 특성을 말한다. 앞의 코드에서 공간을 나타내는 배열 arr의 각 요소들에 i가 할당되며 해당 배열에 연속적으로 접근함을 할 수 있다.
캐시히트와 캐시미스
캐시에서 원하는 데이터를 찾으면 캐시히트라고 하고, 데이터를 찾지 못하고 메모리로 가서 데이터를 찾는 것을 캐시미스라고 한다.
캐시 히트를 하게 되면 데이터를 제어장치를 거쳐 가져오게 된다. 캐시 히트의 경우 위치도 가깝고 CPU 내부 버스를 기반으로 작동하기 때문에 빠르다. 반면에 캐시 미스가 발생하면 메모리에서 가져오게 되는데, 이는 시스템 버스를 기반으로 작동하기 때문에 느리다.
캐시매핑
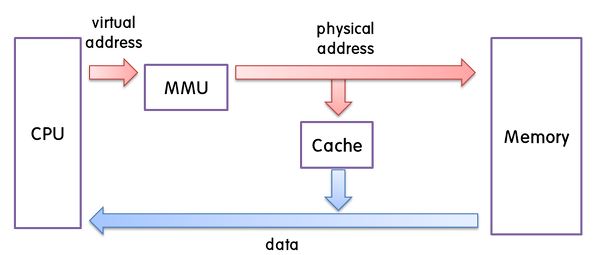
CPU가 메모리 주소를 사용하여 메모리로 데이터를 받으려고 한다.
하지만 CPU가 쓰는 주소는 가상 메모리 주소로 메모리 입장에서는 외계어이다.
따라서 중간에 메모리 관리 장치(MMU)가 가운데에서 번역을 하여 메모리가 알아먹을 수 있는 물리주소로 변환해 준다.
그리고 캐시에 해당 주소에 대한 데이터가 있는지 확인을 하는데 캐시에 데이터를 저장하는 방식에 따라 물리주소를 다르게 해석할 수 있다.
직접 매핑(Direct Mapping)

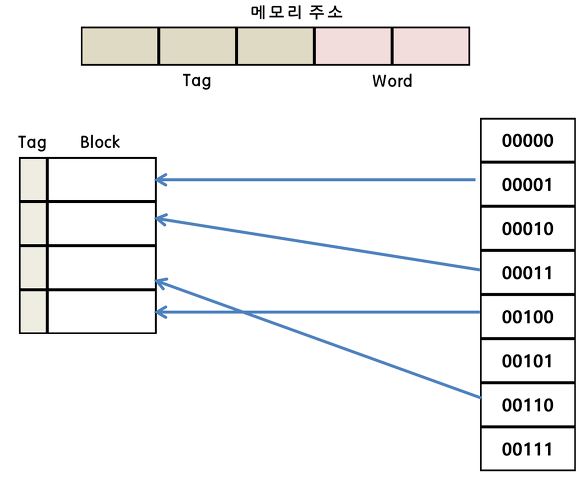
우선 메인 메모리에서 캐시로 데이터를 저장할 때 참조의 지역성 때문에 한번 퍼낼 때 인접한 곳까지 한꺼번에 캐시 메모리에 저장하고 이때 단위를 블록(Block)이라고 한다.
그리고 캐시는 메인 메모리의 몇 번째 블록인지를 알려주는 태그(Tag)도 함께 저장한다.
메모리 주소 중에 가장 뒷부분(붉은색)은 블록의 크기를 의미한다.
지금 블록의 크기가 4이므로 뒤의 두자리를 사용하여 블럭의 크기를 표현하였다.
그리고 이 영역은 블럭의 몇 번째에 원하는 데이터가 있는지 보여주는 지표가 되어준다.
만일 위의 예에서 붉은 영역이 01이라면 블록의 두 번째 내용을 CPU에서 요청한 것이다.
같은 라인에 위치하는 데이터는 파란색 색칠한 영역에 의하여 구별이 가능하다.
예를 들면 메모리에 첫 번째 요소 00000과 다섯 번째 주소 00100은 캐시네에 같은 위치에 자리 잡고 있어서 구별이 필요한데, 앞의 세 자리 000과 001로 구별을 할 수 있다.
이와 같은 요소의 활용은 캐시 메모리에 저장된 데이터 중 내가 원하는 것이 있는지 없는지 확인이 가능하다.
- 캐시의 태그와 주소상의 태그가 동일한지 확인한 후 같으면 붉은 영역을 통해 데이터를 읽는다.
- 만일 태그가 다르다면 메모리에서 데이터를 가지고 온다.
직접 매핑은 위의 사진처럼 캐시에 저장된 데이터들은 메인 메모리에서와 동일한 배열을 가지도록 매핑하는 방법을 말한다.
이와 같은 방식을 사용하기 때문에 매우 단순하고 탐색이 쉽다는 장점이 있다.
하지만 적중률(hit ratio)이 낮다는 단점이 있다.
연관 매핑(Associative Mapping)
연관 매핑은 직접 매핑의 단점을 보완하기 위해 등장하였다.
캐시에 저장된 데이터들은 메인 메모리의 순서와는 아무런 관련이 없다.
이런 방식을 사용하기 때문에 캐시를 전부 뒤져서 태그가 같은 데이터가 있는지 확인해야 한다.
따라서 병렬 검사를 위해 복잡한 회로를 가지고 있는 단점(시간이 오래 걸림)이 있지만 적중률이 높다는 장점이 있다.
세트 연관 매핑(set-associative Mapping)
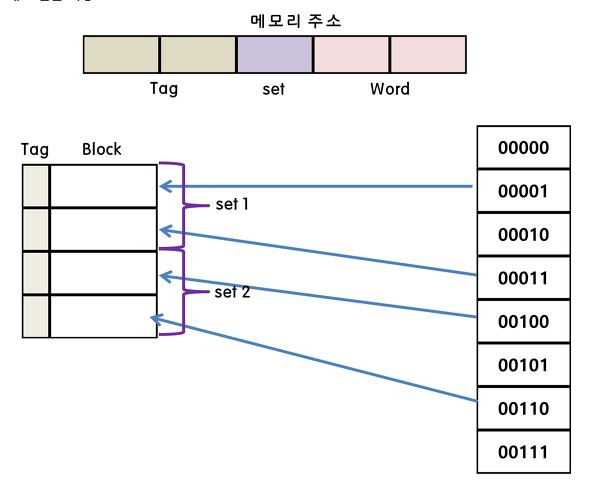
직접 매핑의 단순한 회로와 연관 매핑의 적중률 두 개의 장점만을 취하기 위해서 만들어진 방식이다.
각각의 라인들은 하나의 세트에 속해 있다.
세트 번호를 통해 영역을 탐색하므로 연관 매핑의 병렬 탐색을 줄일 수 있다.
그리고 모든 라인에 연관 매핑처럼 무작위로 위치하여 직접매핑의 단점도 보안하였다.
세트 안의 라인 수에 따라 n-way 연관 매핑이라고 한다.
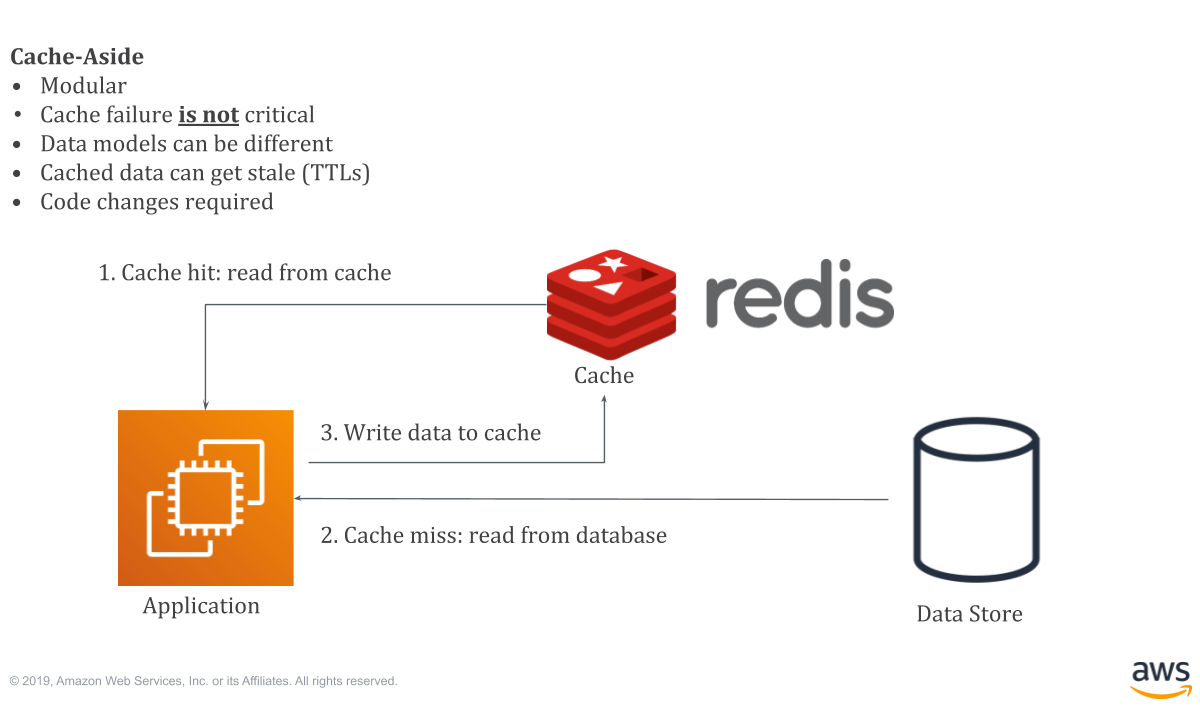
데이터베이스의 캐싱 계층
데이터베이스 시스템을 구축할 때도 메인 데이터베이스 위에 레디스(redis) 데이터베이스 계층을 '캐싱 계층'으로 둬서 성능을 향상하기도 한다.
참고 자료:
http://itnovice1.blogspot.com/2019/09/cache.html
[컴퓨터구조] 캐시 메모리(CACHE)와 매핑 방법 & 일관성
[컴퓨터구조] 캐시 메모리(CACHE)와 매핑 방법 & 일관성 Cache Memory 빠른 CPU, 느린 Memory 프로그램을 CPU 혼자서 수행하는 것이 아니라 메모리도 같이 참여한다. 용량은 Cache < Main Memor...
itnovice1.blogspot.com
https://product.kyobobook.co.kr/detail/S000001834833
면접을 위한 CS 전공지식 노트 | 주홍철 - 교보문고
면접을 위한 CS 전공지식 노트 | 디자인 패턴, 네트워크, 운영체제, 데이터베이스, 자료 구조, 개발자 면접과 포트폴리오까지!CS 전공지식 습득과 면접 대비, 이 책 한 권이면 충분하다! 개발자 면
product.kyobobook.co.kr
https://www.knot35.com/how-to-install-and-configure-redis-cache-on-debian-ubuntu-server/
How To Install and Configure Redis Cache on Debian/Ubuntu Server - KNOT35
If you’re currently running WordPress site with W3-Total-Cache plugin you may know Redis act a Database Cache module inside the […]
www.knot35.com
'백엔드 > 운영체제' 카테고리의 다른 글
| [운영체제] 운영체제(OS) 메모리 관리 - (1) 불연속 메모리 할당, 페이징 (0) | 2023.04.27 |
|---|---|
| [운영체제] 운영체제(OS) 메모리 관리 - (1) 연속 메모리 할당 (0) | 2023.04.26 |
| [운영체제] 메모리 계층 구조 (Memory Hierarchy) (0) | 2023.04.25 |
| [운영체제] 운영체제(OS), 시스템 콜(System Call) (0) | 2023.04.25 |
| [운영체제] 세마포어(semaphore) 뮤텍스(mutex) 모니터(Monitor) (0) | 2023.04.24 |
캐시란?
캐시(cache)는 데이터를 미리 복사해 놓는 임시 저장소이자 빠른 장치와 느린 장치에서 속도 차이에 따른 병목 현상을 줄이기 위한 메모리를 말한다. 이를 통해 데이터를 접근하는 시간이 오래 걸리는 경우를 해결하고 무언가를 다시 계산하는 시간을 절약할 수 있다.
실제로 메모리와 CPU 사이의 속도 차이가 너무 크기 때문에 그 중간에 레지스터 계층을 둬서 속도 차이를 해결한다.
이렇게 속도차이를 해결하기 위해 계층과 계층사이에 있는 계층을 캐싱 개층이라고 한다.
예를 들어 캐시 메모리와 보조기억장치 사이에 있는 주기억장치를 보조기억장치의 캐싱 계층이라고 할 수 있다.
지역성의 원리
캐시 계층을 두는 것 말고 캐시를 직접 설정할 수 있다.
이는 자주 사용하는 데이터를 기반으로 설정해야 한다. 그렇다면 자주 사용하는 데이터에 대한 근거가 되는 것은 무엇일까?
바로 지역성이다. 지역성은 시간 지역성(temporal locality)과공간 지역성(spatial locality)으로 나뉜다.
시간 지역성
시간 지역성은 최근에 사용한 데이터를 다시 접근하려는 특성을 말한다. 예를 들어 for 반복문으로 이루어진 코드 안의 변수 i에 계속해서 접근이 이루어질 때, 여기서 데이터는 변수 i이고 최근에 사용했기 때문에 계속 접근해서 +1을 연이어하는 것을 볼 수 있다.
let arr = Array.from({length : 10}, ()=> 0);
console.log(arr)
for (let i = 0; i < 10; i += 1) {
arr[i] = i;
}
console.log(arr)
/*
[
0, 0, 0, 0, 0,
0, 0, 0, 0, 0
]
[
0, 1, 2, 3, 4,
5, 6, 7, 8, 9
]
*/공간 지역성
공간 지역성은 최근 접근한 데이터를 이루고 있는 공간이나 그 가까운 공간에 접근하는 특성을 말한다. 앞의 코드에서 공간을 나타내는 배열 arr의 각 요소들에 i가 할당되며 해당 배열에 연속적으로 접근함을 할 수 있다.
캐시히트와 캐시미스
캐시에서 원하는 데이터를 찾으면 캐시히트라고 하고, 데이터를 찾지 못하고 메모리로 가서 데이터를 찾는 것을 캐시미스라고 한다.
캐시 히트를 하게 되면 데이터를 제어장치를 거쳐 가져오게 된다. 캐시 히트의 경우 위치도 가깝고 CPU 내부 버스를 기반으로 작동하기 때문에 빠르다. 반면에 캐시 미스가 발생하면 메모리에서 가져오게 되는데, 이는 시스템 버스를 기반으로 작동하기 때문에 느리다.
캐시매핑
CPU가 메모리 주소를 사용하여 메모리로 데이터를 받으려고 한다.
하지만 CPU가 쓰는 주소는 가상 메모리 주소로 메모리 입장에서는 외계어이다.
따라서 중간에 메모리 관리 장치(MMU)가 가운데에서 번역을 하여 메모리가 알아먹을 수 있는 물리주소로 변환해 준다.
그리고 캐시에 해당 주소에 대한 데이터가 있는지 확인을 하는데 캐시에 데이터를 저장하는 방식에 따라 물리주소를 다르게 해석할 수 있다.
직접 매핑(Direct Mapping)
우선 메인 메모리에서 캐시로 데이터를 저장할 때 참조의 지역성 때문에 한번 퍼낼 때 인접한 곳까지 한꺼번에 캐시 메모리에 저장하고 이때 단위를 블록(Block)이라고 한다.
그리고 캐시는 메인 메모리의 몇 번째 블록인지를 알려주는 태그(Tag)도 함께 저장한다.
메모리 주소 중에 가장 뒷부분(붉은색)은 블록의 크기를 의미한다.
지금 블록의 크기가 4이므로 뒤의 두자리를 사용하여 블럭의 크기를 표현하였다.
그리고 이 영역은 블럭의 몇 번째에 원하는 데이터가 있는지 보여주는 지표가 되어준다.
만일 위의 예에서 붉은 영역이 01이라면 블록의 두 번째 내용을 CPU에서 요청한 것이다.
같은 라인에 위치하는 데이터는 파란색 색칠한 영역에 의하여 구별이 가능하다.
예를 들면 메모리에 첫 번째 요소 00000과 다섯 번째 주소 00100은 캐시네에 같은 위치에 자리 잡고 있어서 구별이 필요한데, 앞의 세 자리 000과 001로 구별을 할 수 있다.
이와 같은 요소의 활용은 캐시 메모리에 저장된 데이터 중 내가 원하는 것이 있는지 없는지 확인이 가능하다.
- 캐시의 태그와 주소상의 태그가 동일한지 확인한 후 같으면 붉은 영역을 통해 데이터를 읽는다.
- 만일 태그가 다르다면 메모리에서 데이터를 가지고 온다.
직접 매핑은 위의 사진처럼 캐시에 저장된 데이터들은 메인 메모리에서와 동일한 배열을 가지도록 매핑하는 방법을 말한다.
이와 같은 방식을 사용하기 때문에 매우 단순하고 탐색이 쉽다는 장점이 있다.
하지만 적중률(hit ratio)이 낮다는 단점이 있다.
연관 매핑(Associative Mapping)
연관 매핑은 직접 매핑의 단점을 보완하기 위해 등장하였다.
캐시에 저장된 데이터들은 메인 메모리의 순서와는 아무런 관련이 없다.
이런 방식을 사용하기 때문에 캐시를 전부 뒤져서 태그가 같은 데이터가 있는지 확인해야 한다.
따라서 병렬 검사를 위해 복잡한 회로를 가지고 있는 단점(시간이 오래 걸림)이 있지만 적중률이 높다는 장점이 있다.
세트 연관 매핑(set-associative Mapping)
직접 매핑의 단순한 회로와 연관 매핑의 적중률 두 개의 장점만을 취하기 위해서 만들어진 방식이다.
각각의 라인들은 하나의 세트에 속해 있다.
세트 번호를 통해 영역을 탐색하므로 연관 매핑의 병렬 탐색을 줄일 수 있다.
그리고 모든 라인에 연관 매핑처럼 무작위로 위치하여 직접매핑의 단점도 보안하였다.
세트 안의 라인 수에 따라 n-way 연관 매핑이라고 한다.
데이터베이스의 캐싱 계층
데이터베이스 시스템을 구축할 때도 메인 데이터베이스 위에 레디스(redis) 데이터베이스 계층을 '캐싱 계층'으로 둬서 성능을 향상하기도 한다.
참고 자료:
http://itnovice1.blogspot.com/2019/09/cache.html
[컴퓨터구조] 캐시 메모리(CACHE)와 매핑 방법 & 일관성
[컴퓨터구조] 캐시 메모리(CACHE)와 매핑 방법 & 일관성 Cache Memory 빠른 CPU, 느린 Memory 프로그램을 CPU 혼자서 수행하는 것이 아니라 메모리도 같이 참여한다. 용량은 Cache < Main Memor...
itnovice1.blogspot.com
https://product.kyobobook.co.kr/detail/S000001834833
면접을 위한 CS 전공지식 노트 | 주홍철 - 교보문고
면접을 위한 CS 전공지식 노트 | 디자인 패턴, 네트워크, 운영체제, 데이터베이스, 자료 구조, 개발자 면접과 포트폴리오까지!CS 전공지식 습득과 면접 대비, 이 책 한 권이면 충분하다! 개발자 면
product.kyobobook.co.kr
https://www.knot35.com/how-to-install-and-configure-redis-cache-on-debian-ubuntu-server/
How To Install and Configure Redis Cache on Debian/Ubuntu Server - KNOT35
If you’re currently running WordPress site with W3-Total-Cache plugin you may know Redis act a Database Cache module inside the […]
www.knot35.com
'백엔드 > 운영체제' 카테고리의 다른 글
| [운영체제] 운영체제(OS) 메모리 관리 - (1) 불연속 메모리 할당, 페이징 (0) | 2023.04.27 |
|---|---|
| [운영체제] 운영체제(OS) 메모리 관리 - (1) 연속 메모리 할당 (0) | 2023.04.26 |
| [운영체제] 메모리 계층 구조 (Memory Hierarchy) (0) | 2023.04.25 |
| [운영체제] 운영체제(OS), 시스템 콜(System Call) (0) | 2023.04.25 |
| [운영체제] 세마포어(semaphore) 뮤텍스(mutex) 모니터(Monitor) (0) | 2023.04.24 |