
Kafka Connect란?
Kafka는 Producer/Consumer를 통해 데이터 파이프라인을 만들 수 있다. 예를 들어, A서버 DB에 저장한 데이터를 B서버의 DB로도 보낼 수 있다.
이러한 파이프라인이 여러 개면 매번 반복적으로 파이프라인을 구성해줘야 한다.
Kafka Connect는 이러한 반복적인 파이프라인 구성을 쉽고 간편하게 만들 수 있도록 만들어진 Apache Kafka 프로젝트 중 하나다.
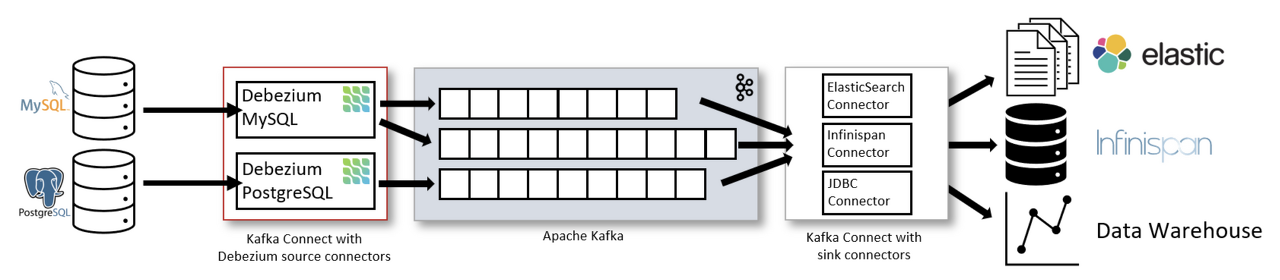
위 사진을 보면 Kafka Connect를 이용해 왼쪽의 DB데이터를 Source Connector를 이용해 Kafka Broker로 보내고 Sink Connect를 이용해 Kafka에 담긴 데이터를 DB에 저장하는 것을 볼 수 있다.
Connect : Connector를 동작하게 하는 프로세서(서버)
Connector : Data Source(DB)의 데이터를 처리하는 소스가 들어있는 jar 파일
Source Connector : data source에 담긴 데이터를 topic에 담는 역할(Producer)을 하는 connector
Sink Connector : topic에 담긴 데이터를 특정 data source로 보내는 역할(Consumer)을 하는 connector
실습
환경
- OS : Windows10
- DB : Mariadb
우선 Mariadb에 테이블을 생성하도록 하자.
CREATE SCHEMA mydb;
CREATE TABLE users(
id INT AUTO_INCREMENT PRIMARY KEY,
user_id VARCHAR(20),
pwd VARCHAR(20),
name VARCHAR(20),
created_at DATETIME DEFAULT NOW()
);Kafka 설치
Kafka downloads에 들어가서 Binary downloads 밑에 Scala 2.13 옆에 있는 tgz 파일을 설치하도록 하자.
필자는 C:\Work 위치에 Kafka 관련 파일들을 저장했다. 설치한 tgz 파일을 Work 디렉토리에 옮긴다.
옮긴 tgz파일을 tar 명령어를 사용해 압축을 해제해 준다.
tar -xvzf kafka_2.13-3.2.1.tgz설치 후 해당 디렉토리로 이동하고 config/server.properties 파일을 열어

listeners=PLAINTEXT://:9092 주석을 풀고 localhost를 입력해 준다.
kafka 디렉토리에서 아래의 명령어를 통해 zookeeper server와 kafka broker를 실행해 준다.
각각 다른 커맨드 창에서 실행시켜 주도록 하자.
Linux/MacOS
./bin/zookeeper-server-start.sh ./config/zookeeper.properties
./bin/kafka-server-start.sh ./config/server.properties
Windows
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
.\bin\windows\kafka-server-start.bat .\config\server.properties
Kafka Connect 설치
다음 명령어를 통해 설치할 수 있다.
curl -O https://packages.confluent.io/archive/7.2/confluent-community-7.2.1.tar.gz설치 후 압축을 풀어 준다.
tar -xvzf confluent-community-7.2.1.tar.gz
압축을 풀어주고 Kafka Connect 디렉토리에서 아래 명령어로 실행할 수 있다.
Linux/MacOS
./bin/connect-distributed ./etc/kafka/connect-distributed.propertiesWindows
.\bin\windows\connect-distributed.bat .\etc\kafka\connect-distributed.properties
오류
필자는 Windows 환경에서 실행했을 때, 다음과 같은 오류가 발생했다.
Classpath is empty. Please build the project first e.g. by running 'gradlew jarAll'kafka connect 디렉토리에서 bin/windows/kafka-run-class.bat 파일을 수정한다.

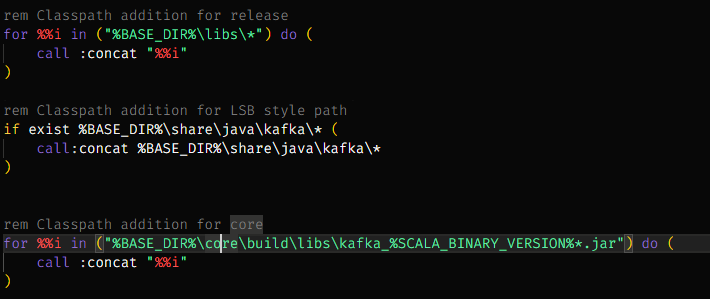
위의 코드 위에 아래 코드를 추가한다.
rem Classpath addition for LSB style path
if exist %BASE_DIR%\share\java\kafka\* (
call:concat %BASE_DIR%\share\java\kafka\*
)
오류 2
log4j:ERROR Could not read configuration file from URL [file:C:/Work/confluent-7.4.0/config/connect-log4j.properties].
java.io.FileNotFoundException: C:\Work\confluent-7.4.0\config\connect-log4j.properties (지정된 경로를 찾을 수 없습니다)kafka connect 디렉토리에서 bin/windows/connect-distributed.bat 파일을 아래와 같이 수정한다.

Connector 설치
confluent JDBC Connector에서 JDBC Connector를 설치한다. 설치를 하면 아래와 같은 디렉토리가 설치된다.
설치 후에 Kafka Connect 디렉토리에서 etc/kafka/connect-distributed.properties 파일을 수정한다.
아래처럼 plugin.path={kafka connect jdbc plugin 경로}/lib을 입력해 준다.

MySQL Connector 설치
connector에서 mysql을 사용하기 위해 추가적으로 mysql connector를 설치해줘야 한다.
mySQL connector/J downloads에서 설치할 수 있다.
https://docs.confluent.io/kafka-connectors/jdbc/current/jdbc-drivers.html를 확인하면
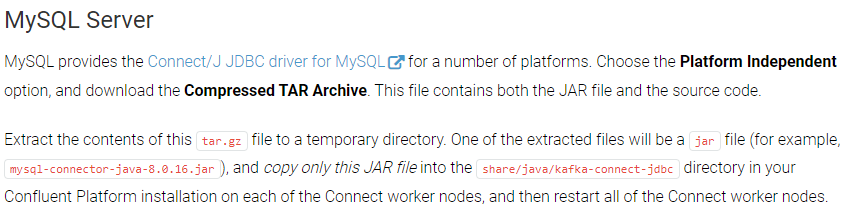
Platform Independent 옵션을 선택하고 TAR 압축 파일을 설치하고 압축해제를 한 후 jar 파일을
Kafka connect 디렉토리에서 share/java/kafka 디렉토리에 복사해 준다.

이제 다시 Kafka Connector를 실행하자.
Source Connector
아래처럼 connect에 요청을 통해 Source Connector를 생성할 수 있다.
필자는 3306 포트를 사용하고 있었기 때문에 3307 포트로 Mariadb를 실행했다.
echo '
{
"name" : "my-source-connect",
"config" : {
"connector.class" : "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url":"jdbc:mysql://localhost:3307/mydb",
"connection.user":"root",
"connection.password":"test1357",
"mode": "incrementing",
"incrementing.column.name" : "id",
"table.whitelist":"users",
"topic.prefix" : "my_topic_",
"tasks.max" : "1"
}
}
' | curl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"포스트맨을 사용하면 다음과 같다.
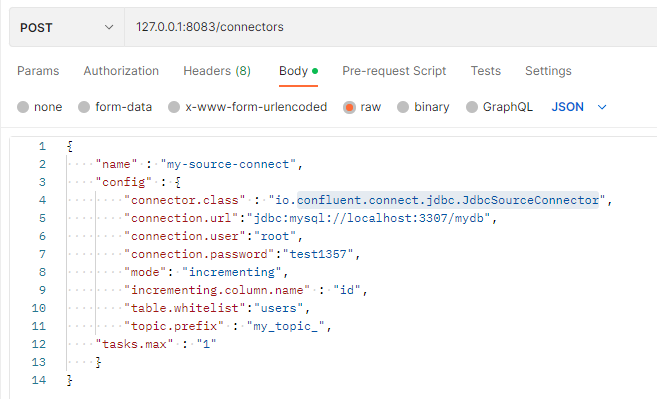
각 속성의 의미는 다음과 같다.
- name : source connector 이름(JdbcSourceConnector를 사용)
- config.connector.class : 커넥터 종류(JdbcSourceConnector 사용)
- config.connection.url : jdbc이므로 DB의 정보 입력
- config.connection.user : DB 유저 정보
- config.connection.password : DB 패스워드
- config.mode : 테이블에 데이터가 추가됐을 때 데이터를 polling 하는 방식 (bluk, incrementing, timestamp, timestamp+incrementing)
- config.incrementing.column.name : incrementing mode일 때 자동 증가 column 이름
- config.topic.prefix : kafka 토픽에 저장될 이름 형식 지정 위 같은 경우 whitelist를 뒤에 붙여 my_topic_users에 데이터가 들어감
- tasks.max : 커넥터에 대한 작업자 수
실행 후 아래 요청을 통해 생성된 Connectors List를 확인할 수 있다.
curl -X GET -d @- http://localhost:8083/connectors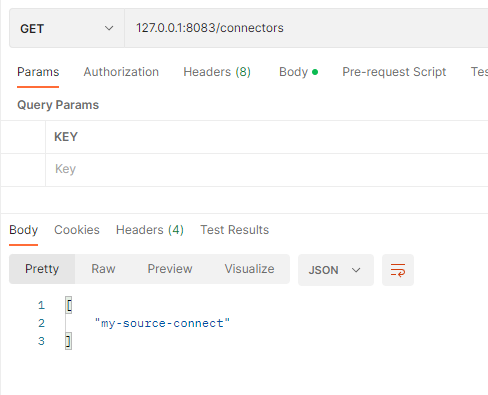
users table에 데이터를 insert 해보자.
그리고 kafka server 디렉토리에서 아래 명령어를 통해 topic 리스트를 확인해 보면 my_topic_users 토픽이 생상 된 것을 확인할 수 있다. (DB에 데이터를 삽입함으로써 Source Connector가 DB 데이터를 topic에 push 한 것)
Linux/MacOS
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
Windows
.\bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --list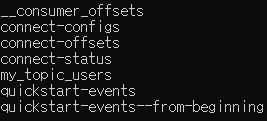
Sink Connector
Source Connector를 통해 topic에 넣은 데이터를 Sink 하기 위해 Sink Connector를 생성해 보자.
echo '
{
"name":"my-sink-connect",
"config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url":"jdbc:mysql://localhost:3307/mydb",
"connection.user":"root",
"connection.password":"test1357",
"auto.create":"true",
"auto.evolve":"true",
"delete.enabled":"false",
"tasks.max":"1",
"topics":"my_topic_users"
}
}
'| curl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"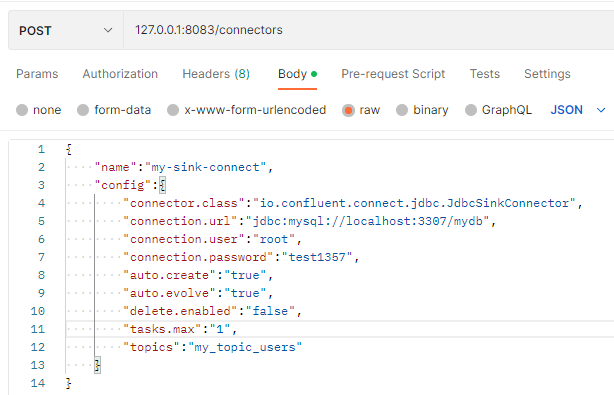
source Connector와 겹치는 속성을 제외한 속성은 다음과 같은 뜻을 가진다.
- auto.create : 데이터를 넣을 테이블이 누락되었을 경우 자동 테이블 생성 여부
- auto.evolve : 특정 데이터의 열이 누락된 경우 대상 테이블에 ALTER 구문을 날려 자동으로 테이블 구조를 바꾸는지 여부 (하지만 데이터 타입 변경, 컬럼 제거, 기본 키 제약 조건 추가등은 시도되지 않는다.)
- delete.enabled : 삭제 모드 여부
더 자세한 속성은 해당 링크에서 확인할 수 있다.
https://docs.confluent.io/kafka-connect-jdbc/current/sink-connector/sink_config_options.html
생성 후 users table에 데이터를 insert 하면
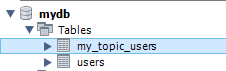
my_topic_users table이 생성된 것을 볼 수 있고
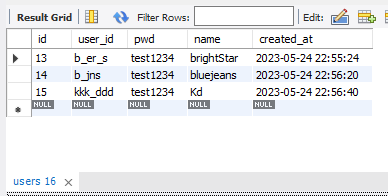
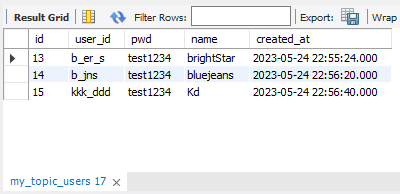
서로 테이블의 내용이 같은 것을 확인할 수 있다.
참고 자료 :
https://cjw-awdsd.tistory.com/53
[Kafka] Kafka Connect 개념/예제
이번 포스팅에서 Kafka의 Connector의 대해 포스팅하고자한다. Kafka Connect란? 먼저 Kafka는 Producer와 Consumer를 통해 데이터 파이프라인을 만들 수 있다. 예를 들어 A서버의 DB에 저장한 데이터를 Kafka Produ
cjw-awdsd.tistory.com
'백엔드 > MSA' 카테고리의 다른 글
| [MSA] Spring Cloud Gateway (0) | 2023.05.13 |
|---|---|
| [MSA] Spring Cloud Netflix Eureka (0) | 2023.05.11 |
| [MSA] Service Discovery (0) | 2023.05.11 |
Kafka Connect란?
Kafka는 Producer/Consumer를 통해 데이터 파이프라인을 만들 수 있다. 예를 들어, A서버 DB에 저장한 데이터를 B서버의 DB로도 보낼 수 있다.
이러한 파이프라인이 여러 개면 매번 반복적으로 파이프라인을 구성해줘야 한다.
Kafka Connect는 이러한 반복적인 파이프라인 구성을 쉽고 간편하게 만들 수 있도록 만들어진 Apache Kafka 프로젝트 중 하나다.
위 사진을 보면 Kafka Connect를 이용해 왼쪽의 DB데이터를 Source Connector를 이용해 Kafka Broker로 보내고 Sink Connect를 이용해 Kafka에 담긴 데이터를 DB에 저장하는 것을 볼 수 있다.
Connect : Connector를 동작하게 하는 프로세서(서버)
Connector : Data Source(DB)의 데이터를 처리하는 소스가 들어있는 jar 파일
Source Connector : data source에 담긴 데이터를 topic에 담는 역할(Producer)을 하는 connector
Sink Connector : topic에 담긴 데이터를 특정 data source로 보내는 역할(Consumer)을 하는 connector
실습
환경
- OS : Windows10
- DB : Mariadb
우선 Mariadb에 테이블을 생성하도록 하자.
CREATE SCHEMA mydb;
CREATE TABLE users(
id INT AUTO_INCREMENT PRIMARY KEY,
user_id VARCHAR(20),
pwd VARCHAR(20),
name VARCHAR(20),
created_at DATETIME DEFAULT NOW()
);Kafka 설치
Kafka downloads에 들어가서 Binary downloads 밑에 Scala 2.13 옆에 있는 tgz 파일을 설치하도록 하자.
필자는 C:\Work 위치에 Kafka 관련 파일들을 저장했다. 설치한 tgz 파일을 Work 디렉토리에 옮긴다.
옮긴 tgz파일을 tar 명령어를 사용해 압축을 해제해 준다.
tar -xvzf kafka_2.13-3.2.1.tgz설치 후 해당 디렉토리로 이동하고 config/server.properties 파일을 열어
listeners=PLAINTEXT://:9092 주석을 풀고 localhost를 입력해 준다.
kafka 디렉토리에서 아래의 명령어를 통해 zookeeper server와 kafka broker를 실행해 준다.
각각 다른 커맨드 창에서 실행시켜 주도록 하자.
Linux/MacOS
./bin/zookeeper-server-start.sh ./config/zookeeper.properties
./bin/kafka-server-start.sh ./config/server.properties
Windows
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
.\bin\windows\kafka-server-start.bat .\config\server.properties
Kafka Connect 설치
다음 명령어를 통해 설치할 수 있다.
curl -O https://packages.confluent.io/archive/7.2/confluent-community-7.2.1.tar.gz설치 후 압축을 풀어 준다.
tar -xvzf confluent-community-7.2.1.tar.gz
압축을 풀어주고 Kafka Connect 디렉토리에서 아래 명령어로 실행할 수 있다.
Linux/MacOS
./bin/connect-distributed ./etc/kafka/connect-distributed.propertiesWindows
.\bin\windows\connect-distributed.bat .\etc\kafka\connect-distributed.properties
오류
필자는 Windows 환경에서 실행했을 때, 다음과 같은 오류가 발생했다.
Classpath is empty. Please build the project first e.g. by running 'gradlew jarAll'kafka connect 디렉토리에서 bin/windows/kafka-run-class.bat 파일을 수정한다.
위의 코드 위에 아래 코드를 추가한다.
rem Classpath addition for LSB style path
if exist %BASE_DIR%\share\java\kafka\* (
call:concat %BASE_DIR%\share\java\kafka\*
)
오류 2
log4j:ERROR Could not read configuration file from URL [file:C:/Work/confluent-7.4.0/config/connect-log4j.properties].
java.io.FileNotFoundException: C:\Work\confluent-7.4.0\config\connect-log4j.properties (지정된 경로를 찾을 수 없습니다)kafka connect 디렉토리에서 bin/windows/connect-distributed.bat 파일을 아래와 같이 수정한다.
Connector 설치
confluent JDBC Connector에서 JDBC Connector를 설치한다. 설치를 하면 아래와 같은 디렉토리가 설치된다.
설치 후에 Kafka Connect 디렉토리에서 etc/kafka/connect-distributed.properties 파일을 수정한다.
아래처럼 plugin.path={kafka connect jdbc plugin 경로}/lib을 입력해 준다.
MySQL Connector 설치
connector에서 mysql을 사용하기 위해 추가적으로 mysql connector를 설치해줘야 한다.
mySQL connector/J downloads에서 설치할 수 있다.
https://docs.confluent.io/kafka-connectors/jdbc/current/jdbc-drivers.html를 확인하면
Platform Independent 옵션을 선택하고 TAR 압축 파일을 설치하고 압축해제를 한 후 jar 파일을
Kafka connect 디렉토리에서 share/java/kafka 디렉토리에 복사해 준다.
이제 다시 Kafka Connector를 실행하자.
Source Connector
아래처럼 connect에 요청을 통해 Source Connector를 생성할 수 있다.
필자는 3306 포트를 사용하고 있었기 때문에 3307 포트로 Mariadb를 실행했다.
echo '
{
"name" : "my-source-connect",
"config" : {
"connector.class" : "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url":"jdbc:mysql://localhost:3307/mydb",
"connection.user":"root",
"connection.password":"test1357",
"mode": "incrementing",
"incrementing.column.name" : "id",
"table.whitelist":"users",
"topic.prefix" : "my_topic_",
"tasks.max" : "1"
}
}
' | curl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"포스트맨을 사용하면 다음과 같다.
각 속성의 의미는 다음과 같다.
- name : source connector 이름(JdbcSourceConnector를 사용)
- config.connector.class : 커넥터 종류(JdbcSourceConnector 사용)
- config.connection.url : jdbc이므로 DB의 정보 입력
- config.connection.user : DB 유저 정보
- config.connection.password : DB 패스워드
- config.mode : 테이블에 데이터가 추가됐을 때 데이터를 polling 하는 방식 (bluk, incrementing, timestamp, timestamp+incrementing)
- config.incrementing.column.name : incrementing mode일 때 자동 증가 column 이름
- config.topic.prefix : kafka 토픽에 저장될 이름 형식 지정 위 같은 경우 whitelist를 뒤에 붙여 my_topic_users에 데이터가 들어감
- tasks.max : 커넥터에 대한 작업자 수
실행 후 아래 요청을 통해 생성된 Connectors List를 확인할 수 있다.
curl -X GET -d @- http://localhost:8083/connectorsusers table에 데이터를 insert 해보자.
그리고 kafka server 디렉토리에서 아래 명령어를 통해 topic 리스트를 확인해 보면 my_topic_users 토픽이 생상 된 것을 확인할 수 있다. (DB에 데이터를 삽입함으로써 Source Connector가 DB 데이터를 topic에 push 한 것)
Linux/MacOS
./bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
Windows
.\bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --listSink Connector
Source Connector를 통해 topic에 넣은 데이터를 Sink 하기 위해 Sink Connector를 생성해 보자.
echo '
{
"name":"my-sink-connect",
"config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSinkConnector",
"connection.url":"jdbc:mysql://localhost:3307/mydb",
"connection.user":"root",
"connection.password":"test1357",
"auto.create":"true",
"auto.evolve":"true",
"delete.enabled":"false",
"tasks.max":"1",
"topics":"my_topic_users"
}
}
'| curl -X POST -d @- http://localhost:8083/connectors --header "content-Type:application/json"source Connector와 겹치는 속성을 제외한 속성은 다음과 같은 뜻을 가진다.
- auto.create : 데이터를 넣을 테이블이 누락되었을 경우 자동 테이블 생성 여부
- auto.evolve : 특정 데이터의 열이 누락된 경우 대상 테이블에 ALTER 구문을 날려 자동으로 테이블 구조를 바꾸는지 여부 (하지만 데이터 타입 변경, 컬럼 제거, 기본 키 제약 조건 추가등은 시도되지 않는다.)
- delete.enabled : 삭제 모드 여부
더 자세한 속성은 해당 링크에서 확인할 수 있다.
https://docs.confluent.io/kafka-connect-jdbc/current/sink-connector/sink_config_options.html
생성 후 users table에 데이터를 insert 하면
my_topic_users table이 생성된 것을 볼 수 있고
서로 테이블의 내용이 같은 것을 확인할 수 있다.
참고 자료 :
https://cjw-awdsd.tistory.com/53
[Kafka] Kafka Connect 개념/예제
이번 포스팅에서 Kafka의 Connector의 대해 포스팅하고자한다. Kafka Connect란? 먼저 Kafka는 Producer와 Consumer를 통해 데이터 파이프라인을 만들 수 있다. 예를 들어 A서버의 DB에 저장한 데이터를 Kafka Produ
cjw-awdsd.tistory.com
'백엔드 > MSA' 카테고리의 다른 글
| [MSA] Spring Cloud Gateway (0) | 2023.05.13 |
|---|---|
| [MSA] Spring Cloud Netflix Eureka (0) | 2023.05.11 |
| [MSA] Service Discovery (0) | 2023.05.11 |