
Redis 캐시 전략
이전 Redis의 글에서 레디스의 캐시 활용에 대해서 알아봤는데, 이번에는 캐시 배치 전략 종류에 대해서 더 상세히 알아보고, redis에서 캐쉬를 다룰 때 어떤 점을 유의해서 설계해야 되는지 적절한 캐싱 전략 선택 지침 이론을 정리해 본다.
캐시는 일반적으로 메모리(RAM)를 사용하기 때문에 데이터베이스 보다 훨씬 빠르게 데이터를 응답할 수 있어 이용자에게 빠르게 서비스를 제공할 수 있다.
하지만 기본적으로 RAM의 용량은 커봐야 16~32GB 정도라, 데이터를 모두 캐시에 저장해 버리면 용량 부족 현상이 일어나 시스템이 다운될 수 있다.
따라서 어느 종류의 데이터를 캐시에 저장할지, 얼마큼 데이터를 캐시에 저장할지, 얼마동안 오래된 데이터를 캐시에서 제거하는지에 대한 '지침 전략'을 숙지할 필요가 있다.
캐시를 효율적으로 사용하기 위해서는 자주 조회되는 데이터, 결괏값이 자주 변동되지 않고 일정한 데이터, 조회하는데 연산이 필요한 데이터를 캐싱해 두면 좋다.
캐시 전략 패턴 종류
캐시를 이용하게 되면 반드시 데이터 정합성 문제가 생긴다.
데이터 정합성은 어느 한 데이터가 캐시와 데이터베이스 이 두 곳에서 같은 데이터임에도 불구하고 데이터 정보값이 서로 다른 현상을 말한다.
이전에는 DB에서 데이터 조회와 작성을 처리했기 때문에 정합성 문제가 나타나지 않았지만, 캐시를 사용하게 되면 다른 데이터 저장소를 이용하기 때문에, 결국 두 저장소에서 저장된 값이 서로 다를 수 있는 현상이 일어날 수밖에 없는 것이다.
따라서 적절한 캐시 읽기 전략(Read Cache Strategy)과 캐시 쓰기 전략(Write Cache Stragtegy)을 통해, 캐시와 DB 간의 데이터 불일치 문제를 극복하면서도 빠른 성능을 잃지 않게 하기 위해 고심히 연구를 할 필요가 있다.
캐시 읽기 전략(Read Cache Strategy)
Look Aside 패턴
- 데이터를 찾을 때 우선 캐시에 저장된 데이터가 있는지 우선적으로 확인하는 전략. 만일 데이터가 없으면 DB에서 조회함.
- 반복적인 읽기가 많은 호출에 적합.
- 캐시와 DB가 분리되어 가용되기 때문에 원하는 데이터만 별도로 구성하여 캐시에 저장
- 캐시와 DB가 분리되어 가용되기 때문에 캐시 장애 대비 구성이 되어있음. 만일 redis가 다운되더라도 DB에서 데이터를 가져올 수 있어 서비스 자체는 문제가 없음.
- 대신에 캐시에 붙어있던 connection이 많았다면, redis가 다운된 순간순간적으로 DB로 몰려서 부하 발생.

애플리케이션에서 캐싱을 이용할 때 일반적으로 사용되는 기본적인 캐시 전략이다.
캐시 장애는 대응할 수 있지만 데이터 정합성 문제가 발생할 수 있으며, 초기 조회 시 무조건 Database를 호출해야 하므로 단건 호출 빈도가 높은 서비스에 적합하지 않다. 대신 반복적으로 동일 쿼리를 수행하는 서비스에 적합한 아키텍처이다.
Read Through 패턴
- 캐시에서만 데이터를 읽어오는 전략
- 데이터 동기화를 라이브러리 또는 캐시 제공자에게 위임.
- 따라서 데이터를 조회하는 데 있어 전체적으로 속도가 느림.
- 데이터 조회를 전적으로 캐시에만 의지하므로, redis가 다운될 경우 서비스 이용에 차질이 생길 수 있음.
- 대신에 캐시와 DB 간의 데이터 동기화가 항상 이루어져 데이터 정합성 문제에서 벗어날 수 있음.
- 읽기가 많은 워크로드에 적합

이 방식은 직접적인 데이터베이스 접근을 최소화하고 Read에 대한 소모되는 자원을 최소화할 수 있다.
캐시가 문제가 발생하는 경우에 서비스 중단이 될 수 있기 때문에, Replication 또는 Cluster로 구성하여 가용성을 높여야 한다.
캐시 쓰기 전략(Write Cache Strategy)
Write Back 패턴
- 캐시와 DB 동기화를 비동기하기 때문에 동기화 과정이 생략
- 데이터를 저장할 때 DB에 바로 쿼리 하지 않고, 캐시에 모아서 일정 주기 배치 작업을 통해 DB에 반영
- 캐시에 모아놨다가 DB에 쓰기 때문에 쓰기 쿼리 회수 비용과 부하를 줄일 수 있음.
- Wirte가 빈번하면서 Read를 하는데 많은 양의 Resource가 소모되는 서비스에 적합.
- 데이터 정합성 확보
- 자주 사용되지 않는 불필요한 리소스 저장.
- 캐시에서 오류가 발생하면 데이터를 영구 소실함.

이 전략 또한 캐시에 Replication이나 Cluster 구조를 적용함으로써 Cache 서비스의 가용성을 높이는 것이 좋으며, 캐시 읽기 전략인 Read-Through와 결합하면 가장 최근에 업데이트된 데이터를 항상 캐시에서 사용할 수 있는 혼합 워크로드에 적합하다.
Write Through 패턴
- 데이터베이스와 Cache에 동시에 데이터를 저장하는 전략
- 데이터를 저장할 때 먼저 캐시에 저장한 다음 바로 DB에 저장
- DB 동기화 작업을 캐시에게 위임
- DB와 캐시가 항상 동기화되어 있어, 캐시의 데이터는 항상 최신 상태로 유지
- 캐시와 백업 저장소에 업데이트를 같이 하여 데이터 일관성을 유지할 수 있어서 안정적
- 데이터 유실이 발생하면 안 되는 상황에 적합.
- 자주 사용되지 않는 불필요한 리소스 저장.
- 매 요청마다 두 번의 Write가 발생하게 됨으로써 빈번한 생성, 수정이 발생하는 서비스에서는 성능 이슈발생
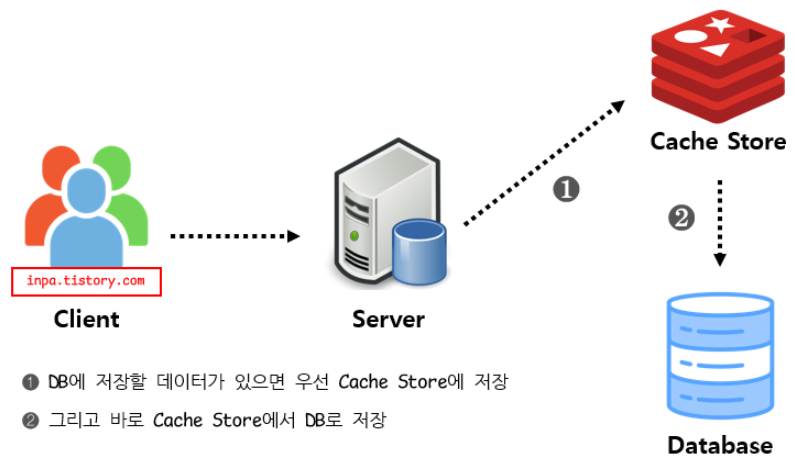
저장할 때마다 2단계 과정을 거쳐지기 때문에 상대적으로 느리며, 무조건 일단 Cache Store에 저장하기 때문에 캐시를 넣은 데이터를 저장만 하고 사용하지 않을 가능성이 있어서 리소스 낭비 가능성이 있다.
Write Around 패턴
- 모든 데이터는 DB에 저장 (캐시를 갱신하지 않음)
- Cache miss가 발생하는 경우에만 DB와 캐시에도 데이터를 저장
- 따라서 캐시와 DB 내의 데이터가 다를 수 있음

속도는 빠르지만, cache miss가 발생하기 전에 데이터베이스에 저장된 데이터가 수정되었을 때, 사용자가 조회하는 cache와 데이터베이스 간의 데이터 불일치가 발생하게 된다.
따라서 데이터베이스에 저장된 데이터가 수정, 삭제될 때마다 Cache 또한 삭제하거나 변경해야 하며, Cache의 expire를 짧게 조정하는 식으로 대처해야 한다.
캐시 읽기 + 쓰기 전략 조합
Look Aside + Write Around 조합
- 가장 일반적인 조합

Read Through + Write Around 조합
- 데이터 정합성 이슈에 대한 완벽한 안전장치를 구성할 수 있음

Read Through + Wrtie Through 조합
- 항상 최신 캐시 데이터 보장
- 데이터 정합성 보장

캐시 저장 방식 지침
캐시 솔루션은 자주 사용되면서 자주 변경되지 않는 데이터의 경우 캐시 서버에 적용하여 반영할 경우 높은 성능 향상을 이뤄낼 수 있다.
메모리를 1차 저장소로 사용하기 때문에 제약적인 저장 공간을 사용하게 된다.
이는 결국 자주 사용되는 데이터를 어떻게 뽑아 캐시에 저장하고 자주 사용하지 않는 데이터를 어떻게 제거해 나갈 것이냐를 지속적으로 고민해야 할 필요성이 있다.
따라서 캐시를 저장하는 시점은 자주 사용되며 자주 변경되지 않는 데이터를 기준으로 하는 것이 좋다.
더 고민해야 할 사항은 캐시 솔루션은 데이터가 날라 갈 수 있는 휘발성을 기본으로 한다는 것이다.
이는 주기적으로 디스크에 데이터를 저장함으로써 어느 정도 해결할 수 있지만, 실시간으로 모든 데이터를 디스크에 저장할 경우 성능 저하를 일으 킬 수 있어 어느 정도 데이터 수집과 저장 주기를 가지도록 설계해야 한다.
데이터 유실 또는 정합성이 깨질 수 있다는 점을 고려해 중요한 정보, 민감 정보 등은 저장하지 않는 것이 좋으며, 캐시 솔루션이 장애가 발생했을 경우 적절한 대응방안을 모색해 두는 것이 바람직하다.
캐시 제거 방식 지침
캐시 만료 정책이 제대로 구현되지 않은 경우에 클라이언트는 데이터가 변경되었음에도 오래된 정보가 캐싱되어 있어 오래된 정보를 사용할 수 있다는 문제점이 발생한다.
따라서 캐시를 구성할 때 기본 만료 정책을 설정해야 한다.
그래서 캐시 만료 주기가 너무 짧으면 데이터는 너무 빨리 제거되고 캐시를 사용하는 이점은 줄어든다.
반대로 너무 기간이 길면 데이터가 변경될 가능성과 메모리 부족 현상이 발생하거나, 자주 사용되어야 하는 데이터가 제거되는 등의 역효과를 나타낼 수도 있다.
Cache Stampede 현상

대규모 트래픽 환경에서 TTL 값이 너무 작게 설정하면 발생할 수 있는 현상이다.
Look-aside 패턴에서 redis에 데이터가 없다는 응답을 받은 서버가 직접 DB로 데이터를 요청한 뒤, 다시 redis에 저장하는 과정을 거친다.
그런데 key가 만료되는 순간 많은 서버에서 이 key를 같이 보고 있었다면 모든 어플리케이션 서버에서 DB로 가서 찾게 되는 duplicate read가 발생한다.
또 읽어온 값을 각 각 redis에 쓰는 duplicate write도 발생되어, 처리량도 다 같이 느려질 뿐 아니라 불필요한 작업이 굉장히 늘어나 요청량 폭주로 장애로 이어질 가능성도 있다.
캐시 공유 방식 지침
여러 인스턴스의 애플리케이션이 캐시에서 데이터를 읽고 수정할 수 있다.
따라서 한 인애플리케이션이 데이터를 수정해야 하는 경우, 애플리케이션의 한 인스턴스가 만드는 업데이트가 다른 인스턴스가 만든 변경을 덮어쓰지 않도록 해야 한다.
그렇지 않으면 데이터 정합성 문제가 발생한다. (각 애플리케이션마다 표시되는 개수가 달라지는 현상)
첫 번째로 캐시 데이터를 변경하기 직전에 데이터가 검색된 이후 변경되지 않았는지 일일이 확인하는 방법이다.
변경되지 않았다면 즉시 업데이트하고 변경되었다면 업데이트 여부를 애플리케이션 레벨에서 결정하도록 수정한다.
이와 같은 방식은 업데이트가 드물고 충돌이 발생하지 않는 상황에 적용하기 용이하다.
두 번째로, 캐시 데이터를 업데이트하기 전에 Lock을 잡는 방식이다.
이와 같은 경우 조회성 업무를 처리하는 서비스에 Lock으로 인한 대기현상이 발생한다.
이 방식은 데이터의 사이즈가 작아 빠르게 업데이트가 가능한 업무와 빈번한 업데이트가 발생하는 상황에 적용하기 용이하다.
참고 자료 :
[REDIS] 📚 캐시(Cache) 설계 전략 지침 💯 총정리
Redis - 캐시(Cache) 전략 캐싱 전략은 웹 서비스 환경에서 시스템 성능 향상을 기대할 수 있는 중요한 기술이다. 일반적으로 캐시(cache)는 메모리(RAM)를 사용하기 때문에 데이터베이스 보다 훨씬 빠
inpa.tistory.com
'백엔드 > 데이터베이스' 카테고리의 다른 글
| [데이터베이스] 레디스(Redis) (1) | 2023.06.08 |
|---|